
Research on over-approximations with previews for correct-by-construction control
This blog post outlines my contributions to correct-by-construction control through the use of over-approximations with preview information. It will play a central role in my research project. This work is currently under review and is also available as a preprint.
- Antoine Aspeel, Antoine Girard, Thiago Alves Lima. Exploiting Over-Approximation Errors as Preview Information for Nonlinear Control.
We are interested in known nonlinear and deterministic dynamical systems under state and input constraints. Since the dynamics \(f\) is nonlinear, such a system is hard to control. For that reason, it is approximated by a simpler (e.g., linear or piecewise linear) dynamics \(\hat{f}\) for which synthesizing a safe policy is easier. However, such an approximation introduces an error. The idea of over-approximations is to find a set \(W\subset\mathbb{R}^{n_x}\) that contains all the possible errors over the domain, i.e.,
\[f(x,u)-\hat{f}(x,u)\in W,\ \text{ for all }\ (x,u)\in\mathcal{X}\times\mathcal{U}.\]Instead of controlling the nonlinear system, the idea of over-approximations is to synthesize a policy for the following nondeterministic system:
\[x_{t+1}=\hat{f}(x_t,u_t)+w_t,\]where
\[w_t=f(x_t,u_t)-\hat{f}(x_t,u_t)\in W\]is treated as an unknown disturbance.
An over-approximation replaces a deterministic nonlinear system with a nondeterministic linear system such that the trajectory of the nonlinear system is one of the possible trajectories of the nondeterministic over-approximation. If a control policy guarantees safety for all trajectories of the over-approximation, then the same policy is guaranteed to ensure safety for the original system.
In previous works on over-approximations, the disturbance \(w_t\) is treated as unknown (see e.g., [1],[2]), and a state-feedback policy \(\pi:\mathcal{X}\rightarrow\mathcal{U}\) is designed to complete a control task for any realization of the disturbances. In contrast, in this work we show that the disturbance can be considered as known at runtime, and how it can be exploited by the policy. We make the key observation that at runtime, the state \(x_t\) is known and the input \(u_t\) is a decision variable, consequently, in the light of
\[w_t=f(x_t,u_t)-\hat{f}(x_t,u_t),\]the disturbance \(w_t\) can be considered as known as an input-dependent preview information. Consequently, rather than synthesizing a feedback policy that depends only on the state, one can design a policy that depends jointly on the state and the disturbance, i.e.,
\[u_t=\pi(x_t,w_t).\]Using such a preview-based policy has the potential to reduce conservatism compared with a state-feedback policy, because the control input is chosen by taking strictly more information into account. However, it comes with a few challenges.
Control with preview information refers to control strategies that exploit knowledge on future realizations of the system disturbances. A typical example arises in wind turbine control, where LiDAR measurements are used to anticipate upcoming wind speed fluctuations before they affect the turbine dynamics [3].
In contrast, in our work the preview signal is endogenously generated by the over-approximation error and depends explicitly on the chosen control input. This input-dependent structure induces a coupling between the preview information and the control policy (see Figure).
- Challenge: There is an apparent circularity between the input \(u_t\) and the disturbance \(w_t\). Indeed, the input determines the disturbance, while the disturbance determines the input (see Figure).
Solution: At runtime, once the state \(x_t\) is available, the input \(u_t\) can be chosen by solving \(\text{Find }\ u_t\in\mathcal{U}\ \text{ such that } u_t=\pi(x_t,f(x_t,u_t)-\hat{f}(x_t,u_t)).\)
This ensures that both equations are satisfied. This allowed us to prove that the resulting trajectory of the nonlinear system is guaranteed to be safe.

- Challenge: Problem above must be solved efficiently at runtime, which can be challenging. In addition, it is not even clear that it admits a solution.
Solution: We note that solving this problem reduces to finding a fixed point of the function \(\mathcal{F}_{x_t}:\mathcal{U}\rightarrow\mathcal{U}\) given by
We then rely on fixed-point theory to study this problem. Existence of solutions follows from the Brouwer fixed-point theorem, while efficient computation is enabled through closed-form, linear, or convex programs for input-affine systems, and through an iterative method based on the Banach fixed-point theorem for nonlinear systems.
- Challenge: Synthesizing state-feedback policies is a well-studied problem. However, here we need to synthesize a preview-based policy that depends jointly on the state \(x_t\) and on the disturbance \(w_t\).
Solution: We show that synthesizing a preview-based policy for the over-approximation reduces to synthesizing a state-feedback policy for a properly constructed augmented system.
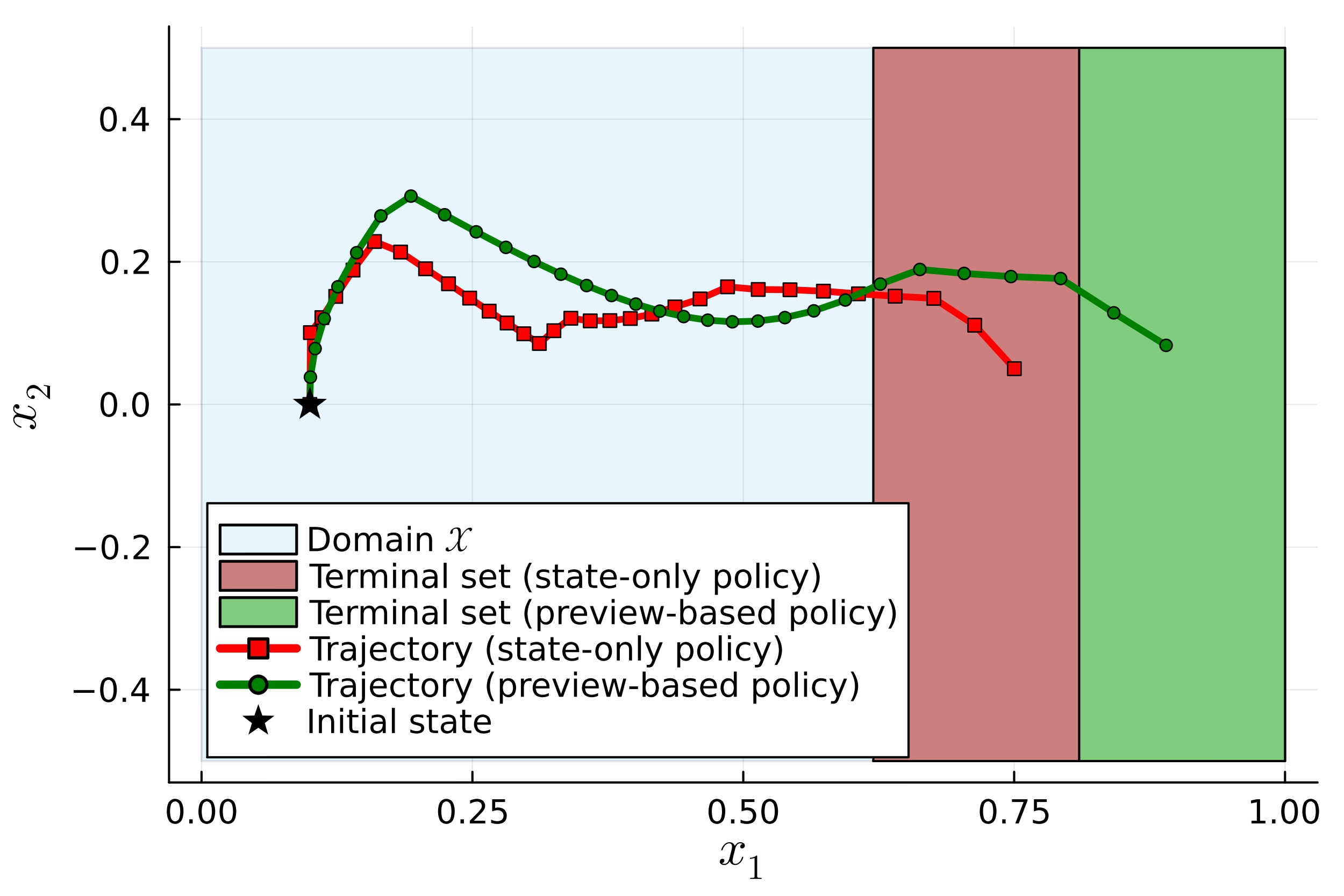
Numerical experiments confirm that a preview-based policy leads to a substantial reduction in conservatism compared with a policy that depends on the state only. See the figure below for a comparison.
References
[1] A. Girard and S. Martin, “Synthesis for constrained nonlinear systems using hybridization and robust controllers on simplices,” IEEE Transactions on Automatic Control, vol. 57, no. 4, pp. 1046–1051, 2011.
[2] M. Althoff, O. Stursberg, and M. Buss, “Reachability analysis of nonlinear systems with uncertain parameters using conservative linearization,” in 2008 47th IEEE Conference on Decision and Control, IEEE, 2008, pp. 4042–4048.
[3] A. A. Ozdemir, P. Seiler, and G. J. Balas, “Design tradeoffs of wind turbine preview control,” IEEE Transactions on Control Systems Technology, vol. 21, no. 4, pp. 1143–1154, 2013.